SIGGRAPH 2026 Conference Track
Mix3R: Mixing Feed-forward Reconstruction and Generative 3D Priors for Joint Multi-view Aligned 3D Reconstruction and Pose Estimation
Siyou Lin, Zhou Xue, Hongwen Zhang, Liang An, Dongping Li, Shaohui Jiao, Yebin Liu
arXiv | Code
Overview
We adopt the Mixture-of-Transformers (MoT) to fuse the pixel-aligned feed-forward model Pi3 and the generative model TRELLIS, achieving sparse multi-view generative reconstruction with better input alignment.
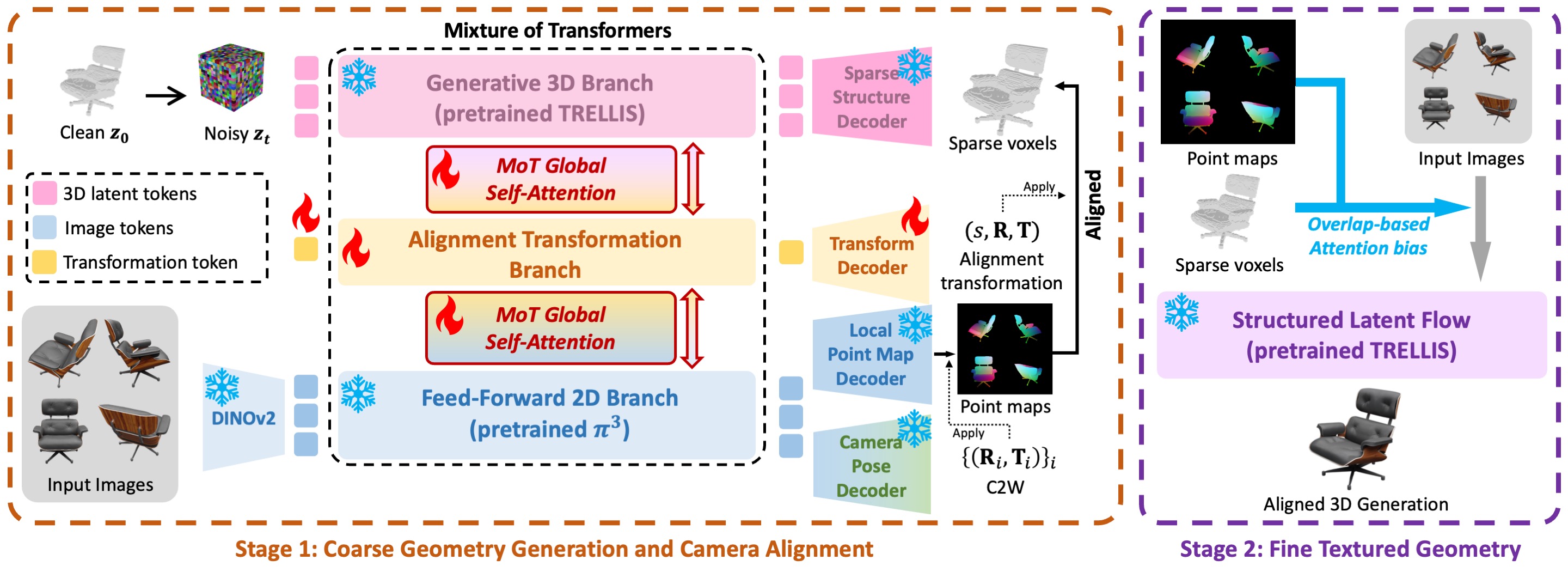
Results (Toys4K and GSO)
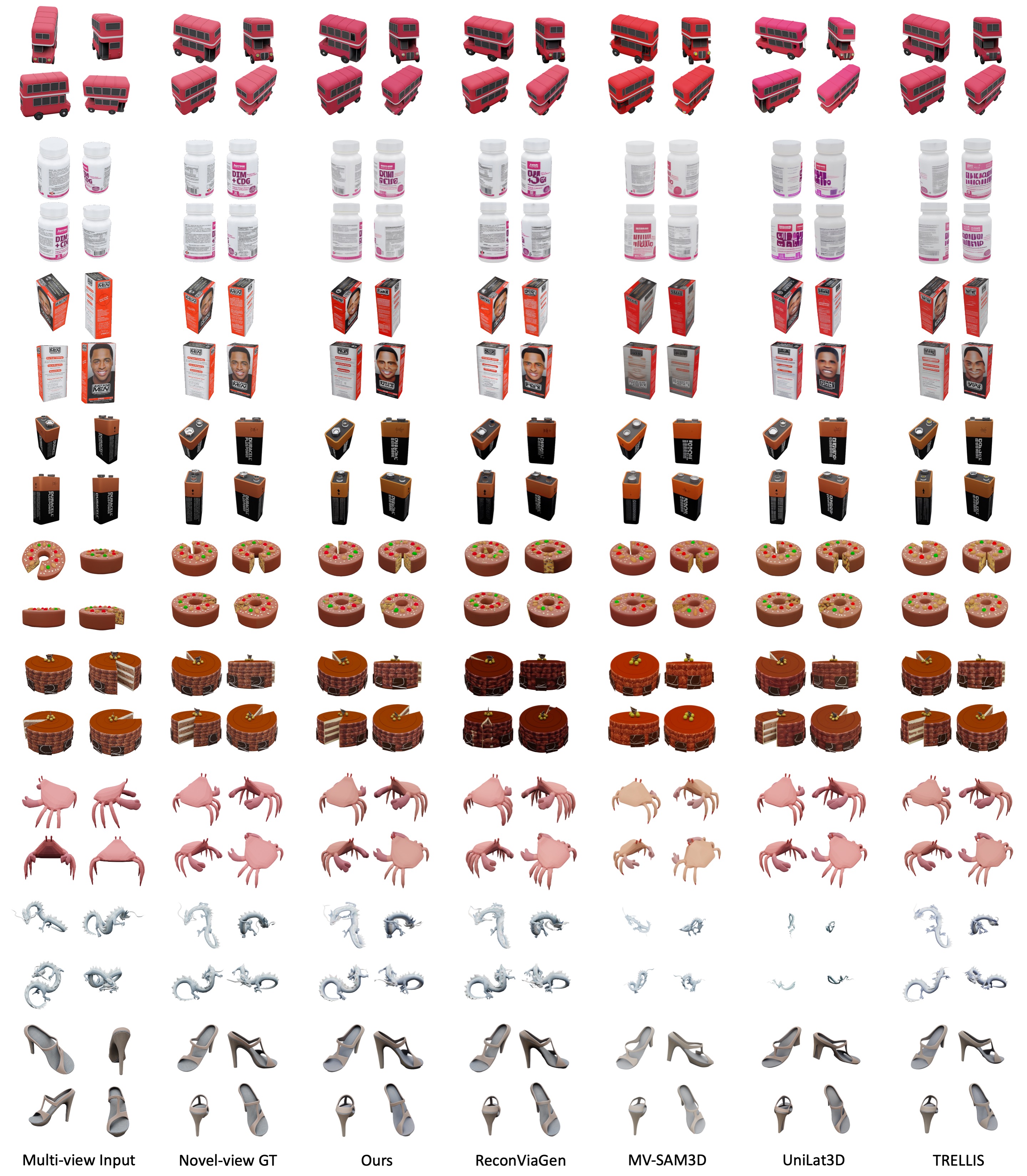

Real-world Captures
